
One of the reasons companies practice Chaos Engineering is to prevent expensive outages in retail (or anywhere, for that matter) from happening in the first place. This blog post walks through a common retail outage where the checkout process fails, then covers how to use Chaos Engineering to prevent the outage from ever happening in the first place.
Let's dive in.
Maybe you've been there. You're a Senior Software Engineer, ready to head home for the weekend, when you receive a high-priority email from customer support: Some users are unable to checkout and are being redirected to a “Sorry, we can’t complete your transaction right now!” error page.
Hoping for an easy fix, and to still have your weekend, you start to investigate. However, a quick check shows no new latency, no obvious errors, and only a slight drop in traffic to the order completed application. The deployment pipelines show no new deployments, and the automated alerting has not indicated any of the normal failures.
Looks like you might be stuck here for a while. So you call your team in, and for the next hour dive deep into the flow—but still, no answers. You're getting frustrated. Eventually, customer support reaches back out with new information: “The affected customers are all using MasterCard, and all appear to be centralized in Italy.”
Ah-ha! It must be the payment processing, which is an external issue! You quickly connect to a regional proxy to test the flow. Sure enough, you're greeted with the correct redirect to the expected payment window, but when a MasterCard credit card is entered, you get the dreaded error message.
You reach out to the credit card processor who confirms that at roughly the same time the first customer error was reported, they had rolled out a new deployment which introduced unexpected latency to a back-end system introducing errors in their API. But don't worry, they tell you, they're rolling back now... Friday night deployments.
Digging in
On Monday morning you and your team meet with the problem management group for a postmortem. The final tally: In just over an hour, $800,000 in gross revenue was lost as a result of the regional MasterCard failure, not to mention the frustration and exhaustion of your team who just spent their entire weekend monitoring the flow.
The good news? The fix is simple: Add a queuing system that retries the purchase for up to an hour before giving up, and update the timeouts to allow for slower responses from the payment processor. Although simple, the fix is estimated to cost $500,000 in developer and implementation costs, creating an overall incident cost of a whopping $1,300,000 and months of slipped commitments. However, your team rests easy knowing this should never happen again.
Still not enough
Of course, one month after the improvements were implemented, the same thing happens again. Your retry fix kicks in, but this time the credit card processor has trouble rolling back their code. And while they struggle, the retries reach their limits causing a new failure: The backlog queue grew too quickly for the databases to manage, and orders began to fail system-wide. Exacerbated by the new architecture's weakness, the gross revenue lost nears $3,000,000.
The first time the system failed, it was unavoidable and unfortunate. The second time, it was entirely avoidable.
So how do you keep this situation from happening to you and your team? How could you avoid not only the second failure, but this entire scenario in the first place? The problem was that when you implemented your fix, it was never tested under real-world conditions. You can catch these types of failures before they happen by using Chaos Engineering to safely recreate the outage conditions and see what happens. Then you will know whether your fix is adequate or if it needs further improvement.
Chaos Engineering
Chaos Engineering is the science of performing intentional experimentation on a system by injecting precise and measured amounts of harm to observe how the system responds for the purpose of improving the system’s resilience. By triggering these failures in a controlled way, you can find and fix your flaws, giving your team confidence both in your product and in its ability to deal with unforeseen failures. Some examples include forcing a reboot of the OS, injecting latency in a request, or changing the host's system time. Companies like Netflix, Amazon, and Salesforce have been using Chaos Engineering for years to build more resilient and reliable systems.
If the developers in our example had used Chaos Engineering to test the dependency on the credit card processor before they went live, they could have easily identified this potential outage and prevented it from ever occurring. Injecting faults into the system would have quickly revealed these limits, allowing the team to fix them before the system went to production.
Specifically, injecting latency and timeouts to the backlog-queue producers would have quickly revealed system dependencies that had not been accounted for. The latency would lead to not only upstream failures, but to the eventual collapse of the entire site. You would have seen that a better fix would have been to tune less critical systems to time out faster, while giving more critical systems alternative paths to completion. And, more importantly, you could have foreseen the collapse of the database.
A properly executed chaos experiment could have saved the company $3,000,000 and months of developer time.
Chaos Engineering on a retail website
Let's look at some specific examples of how you might use Chaos Engineering on a retail website. For our example, we'll use Google’s Online Boutique, a sample microservices-based cloud application that sells trendy products. You can find the working example here. Our retail website uses a modern microservices architecture that breaks out functionality into loosely coupled and discrete services.
Here is an overview of our system:
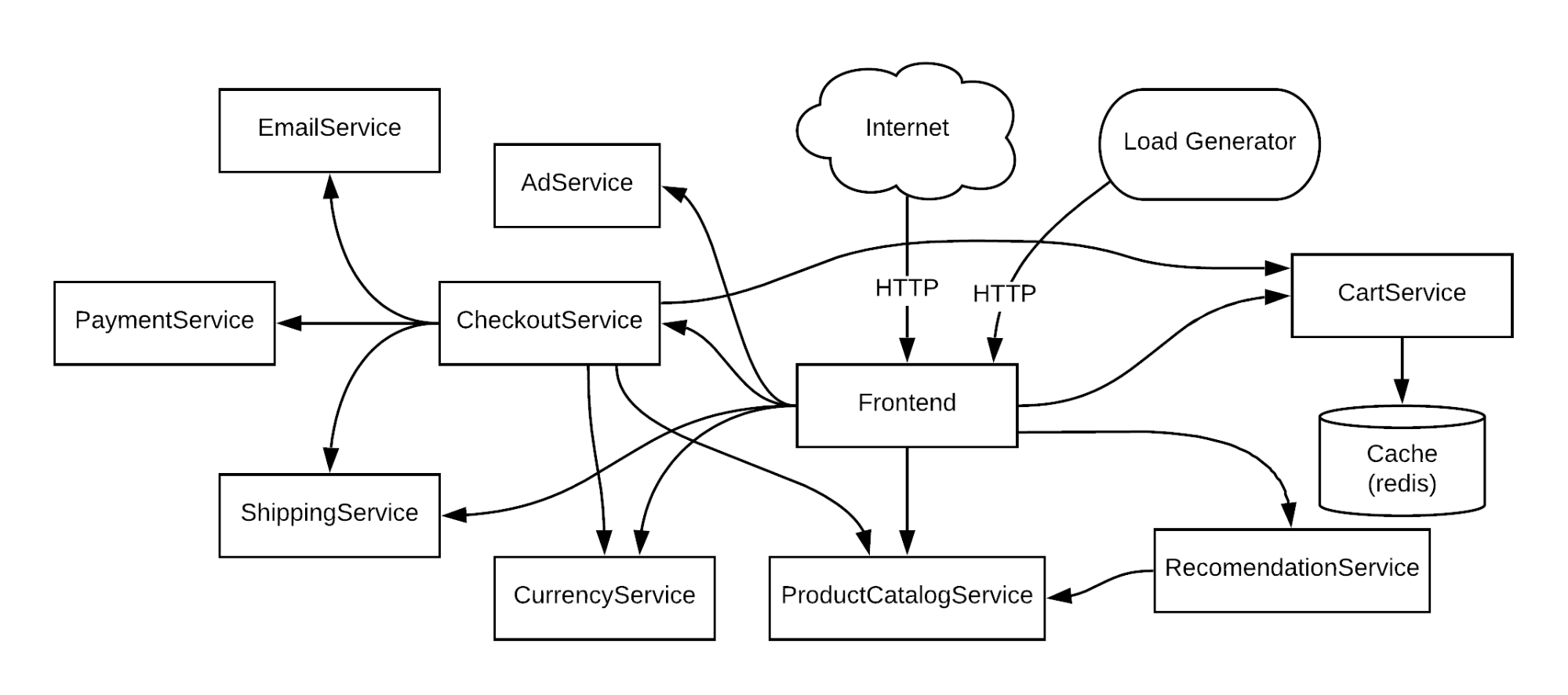
Critical path
Our first step is to identify the critical paths on our website. These are the workflows that are essential to the operation of the website, and of the business. By understanding our critical paths, we can understand what we need to test, and how services affect one another. Using our previous diagram, we can outline our workflows.
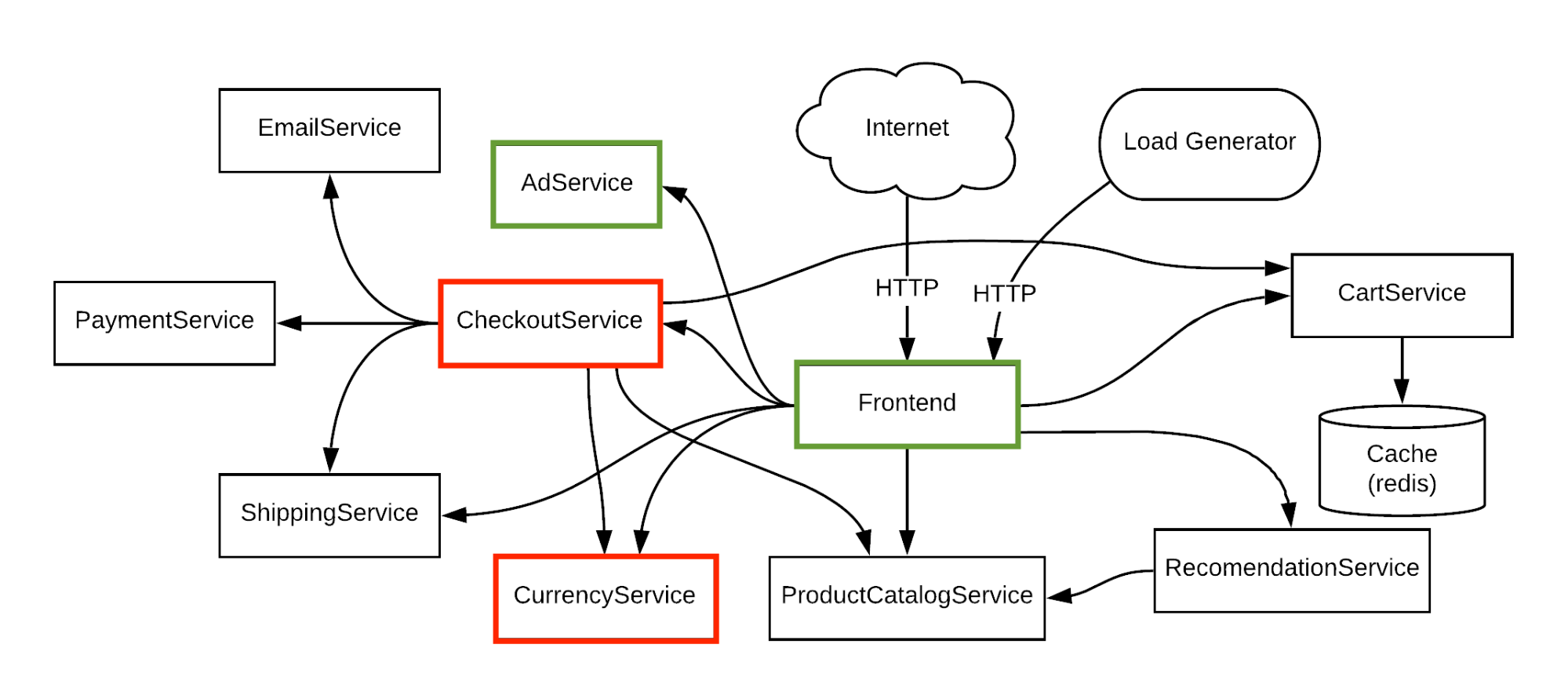
Workflows
The green path above shows a flow from a central dependency (the Frontend) to a single isolated dependency (the AdService). Since the AdService is not core to our business of selling trendy products, its failure should not be a blocker, and the website should work as expected when it is unavailable.
The red path, however, shows a flow of a core business function (the CheckoutService) and a shared dependency on the CurrencyService. The CurrencyService itself is critical to the checkout flow, but should not impact any other flows. It should also have a fail-safe to ensure the CheckoutService can complete even when the CurrencyService is unavailable.
Running chaos experiments
Now that we understand our critical paths and our hypotheses, let's design chaos experiments to thoughtfully inject faults into our system. Randomly breaking your system creates results that are difficult to measure and understand, so it's important to design your chaos experiments carefully. A well-designed chaos experiment follows these steps:
- Plan your experiment
- Create a hypothesis
- Measure the baseline and impact
- Minimize the blast radius and have a rollback plan
- Run the experiment and observe the results
Check out this resource for more information on designing your chaos experiment. For our tests, we've formed our hypothesis and planned our experiments to test both a critical and non-critical path.
We'll use Gremlin, a Chaos Engineering SaaS platform, to run our chaos experiments. You can try these chaos experiments for yourself by creating a Gremlin Free account.
Create your Gremlin Free account
Experiment #1 - Determine the impact of latency on a non-critical service
In this test, we want to understand exactly what will happen if our advertising function slows down. To this end, we'll inject a Gremlin latency attack on all calls to the function, then monitor how our system reacts.
Here is the application working as expected before adding latency to the advertising service. Our hypothesis is that this page should render even if the advertising service (outlined in green below in the UI) is non-responsive or slow to respond.
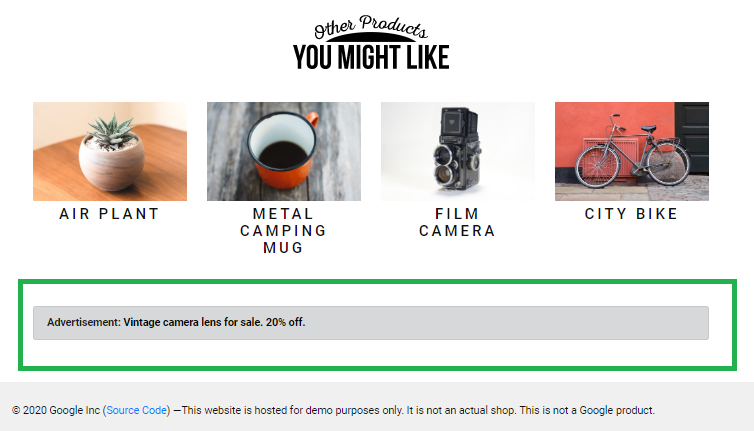
Product page working normally
Using Gremlin, we injected a latency of 100ms to all return calls from the AdService. The result? As expected, the injected latency caused the ad to not render, and when we added more latency, the container itself failed. As we predicted, the latency did not impact the site as a whole, which is a testament to the resiliency of the microservice architecture. With the help of Chaos Engineering, we've validated our understanding of our application behavior when the advertising service is unavailable.
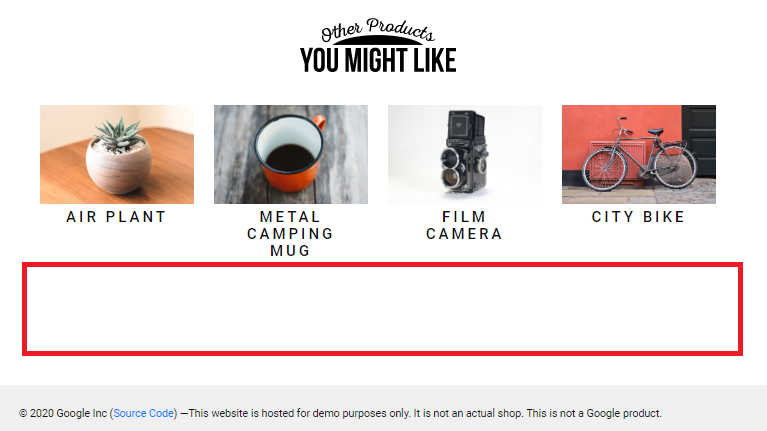
Product page with Ads timeout
Here is the Gremlin setup and summary of the latency attack. The screenshot below shows the setup details:
- The type of attack (Latency)
- The milliseconds injected (100)
- The length of the attack (10 minutes)
- The infrastructure endpoints we were interested in (Frontend to AdService)
- The ingress service IP (into the AdService)
- The specific pod IP serving the traffic
- The physical hosts involved in this injected attack
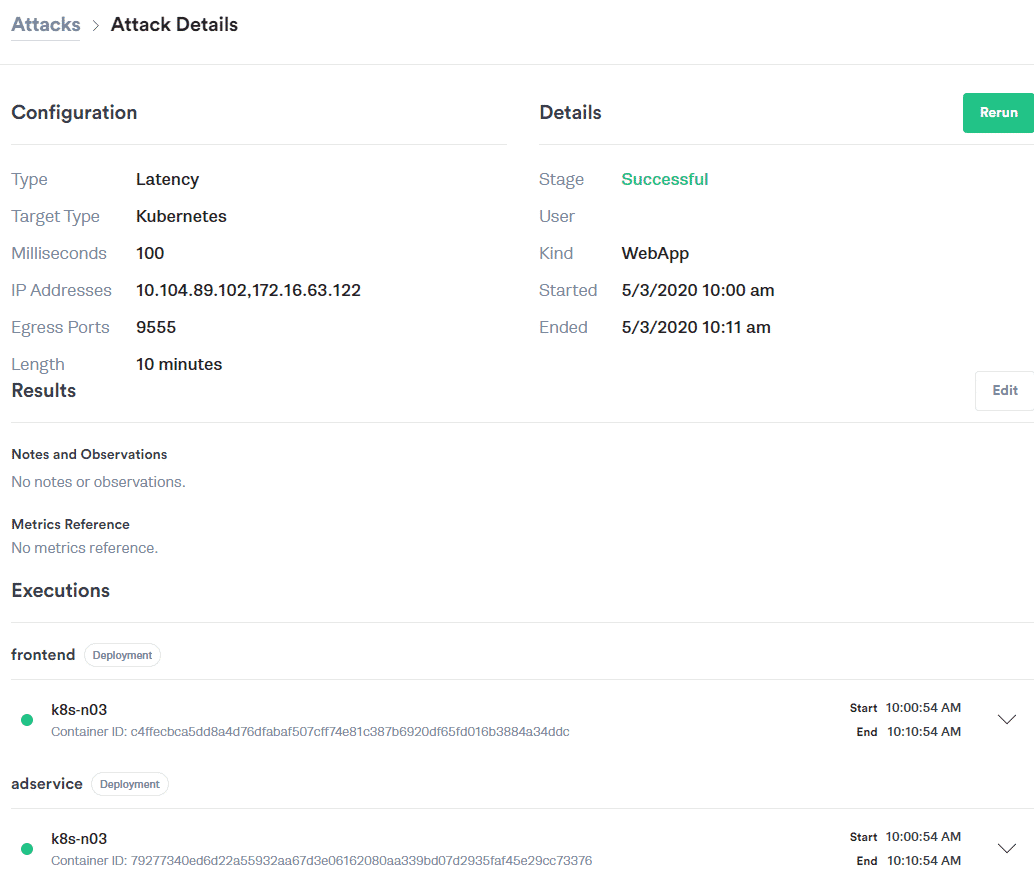
Gremlin Latency attack
Here we can see the latency injection happening in real time from the perspective of the AdService.
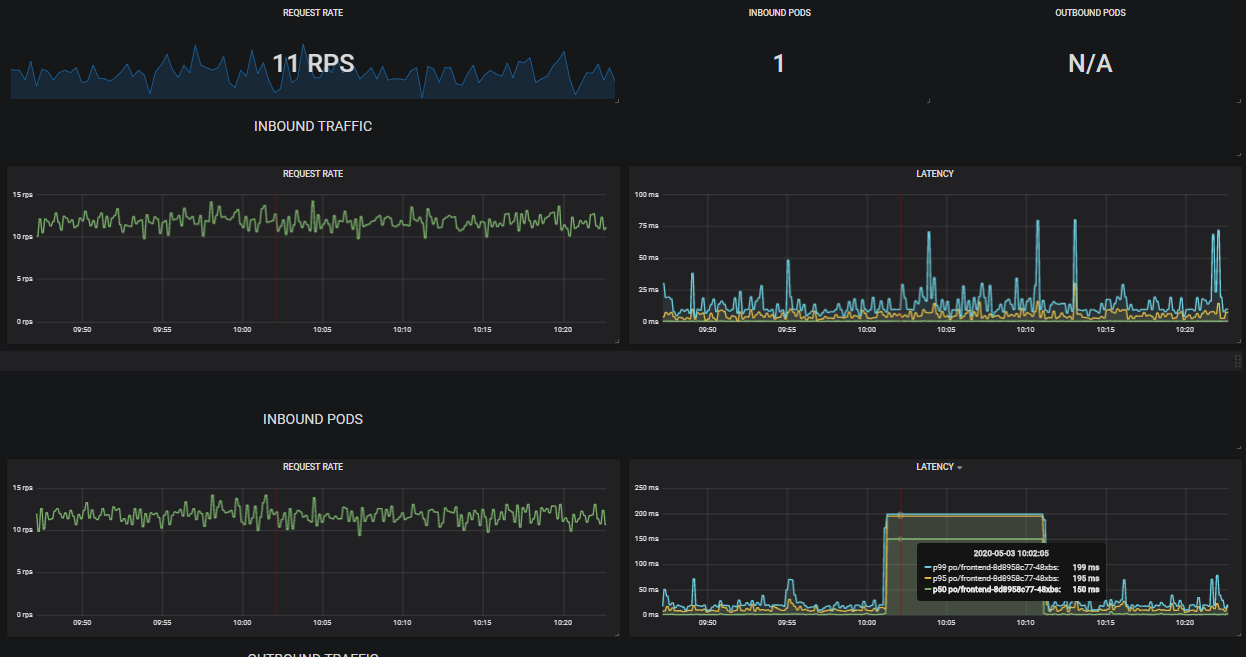
Frontend -> Ad latency injection
Experiment #2 - Determine the impact of a critical path service becoming unavailable
For our second test, we want to understand what happens if a critical path service for our site (the CurrencyService) is unavailable. To do this, we'll create a blackhole test where all packets meant for the CurrencyService are dropped (hence the name "blackhole"). This simulates a network or application outage.
Here is how our checkout flow should end after a successful checkout:
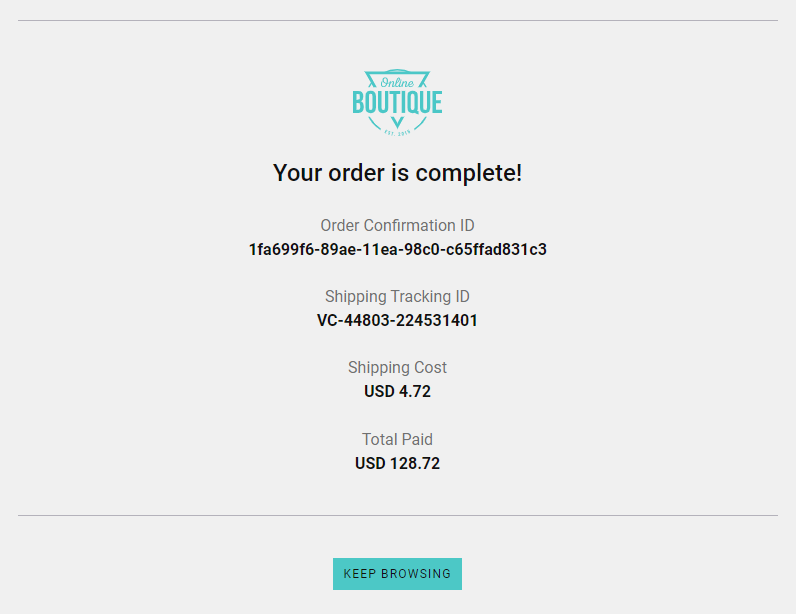
Order complete page with no errors
Now, using Gremlin, we inject our blackhole into the CurrencyService. This time, when we try to check out, the CurrencyService can no longer be reached and we can monitor how our application reacts.
The result? Not only does our checkout process fail, but the blackhole also exposes the chain of dependencies on the CurrencyService. Even the home page and product pages fail, and show the below error:
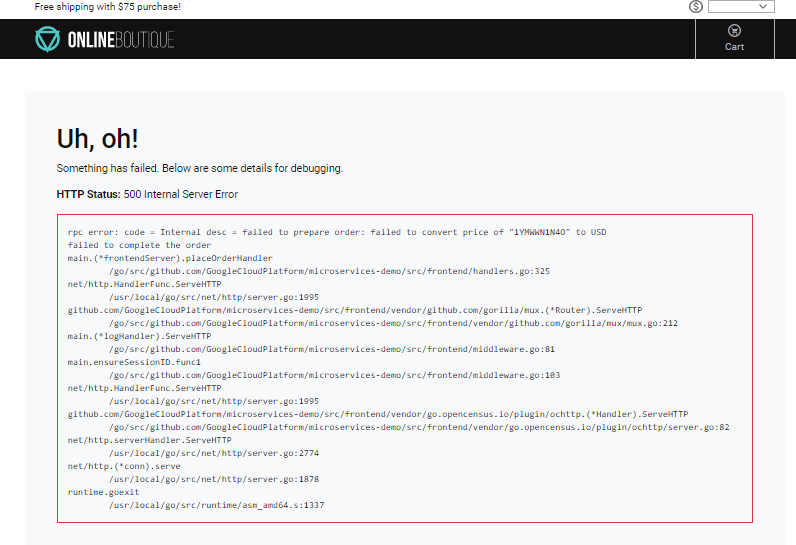
Order complete page with the currency service down
Uh, oh is right!
It’s worth noting that the first time this test ran, the CurrencyService never recovered after we aborted the attack. A manual restart had to be executed. This warns us that if this had been a real incident, even automated recovery mechanisms may not have been enough to resolve the problem.
Here is the Gremlin attack configuration for this test:
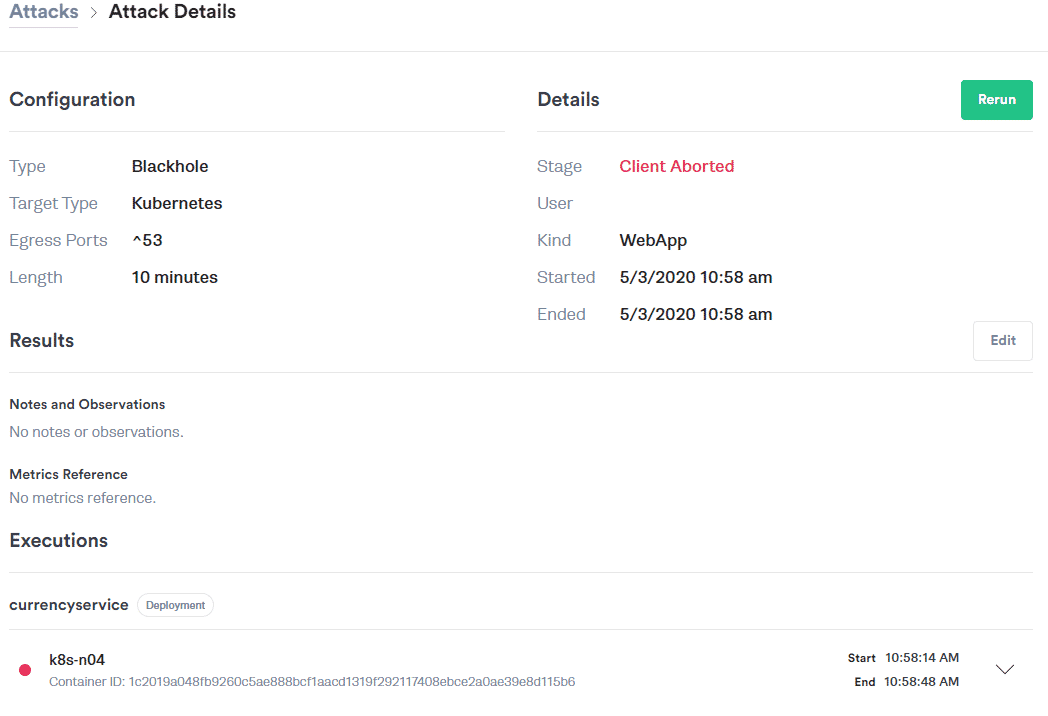
Gremlin blackhole auto-aborted
And here we can see the requests per second drop with a complete loss in successful calls across all features. We also see gaps in reported latency as calls failed due to the dead CurrencyService.
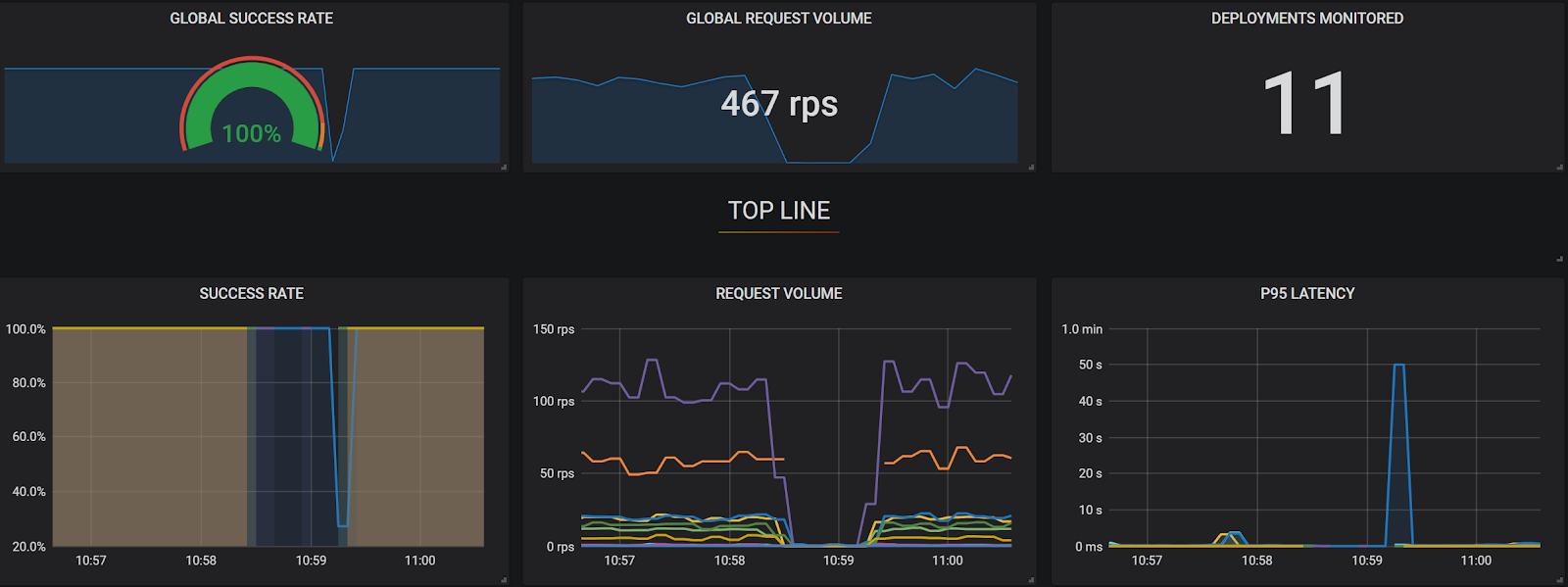
All Dependent services failing due to critical workflow interruption
While currency conversions are something that can be cached locally or retried later in the event of a failure, this was missed in the overall architecture design. However, thanks to our chaos tests, workarounds can be built-in before we see these issues in production.
Conclusion
Uptime is expensive, but incidents are even more so. If it's worth investing time and money into a robust infrastructure, it's worth the upfront investment of using Chaos Engineering to ensure your application performs as expected. Exposing these weaknesses before you deploy to production is key to preemptively identifying issues, not just on your website, but across your fulfillment pipeline. A well-designed Chaos Engineering plan can lower your risk of downtime, save you the costs of lost revenue and engineering time, and help you better serve your customers. See how easy it can be to get started using Gremlin Free.
